Editing Entities
Entities Overview
In IJC, data from database tables are represented by entities. Please look at the documentation pages for more information about IJC’s architecture and terminology. IJC currently supports five types of entities: standard entity, structure entity, SQL entity, pivot entity and web service entity.
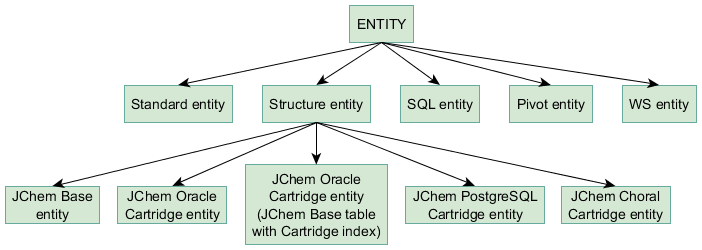
An overview of all types of entities and their characteristic features are included in the following table:
| Entity | Description |
|---|---|
 Standard entity Standard entity |
Standard entities are created on top of normal database tables and views. Can be used to store numeric and textual data in a standard entity. Only basic query functionality is offered by this standard entity. |
 Structure entity Structure entity |
There are five subtypes of structure entities. JChem Base entity, JChem Oracle Cartridge entity, JChem Oracle Cartridge entity (JChem Base table with Cartridge index) (documentation page about the JChem cartridge table types in IJC can be found here), JChem PostgreSQL Cartridge entity and JChem Choral Cartridge entity. |
| SQL entity |
A SQL entity is created using an SQL SELECT statement. |
 Pivot entity Pivot entity |
Creates a virtual data view containing pivoted data from another entity. It is not possible to query this entity directly and it is by default linked to the original entity by 1:N relationship. |
| Web service entity |
Since Instant JChem 21.16.0 version, it is possible to create a virtual data view containing data retrieved from a web service. It is not possible to query this entity directly, but Extension field can be used to define custom operators. Web service entity can be linked to other entities using a Virtual relationship. |
It is also possible to add existing tables which are already present in your database to IJC by promoting them to entities.
If you are using an Oracle database and the Oracle schema which you are connected to has the JChem Oracle Cartridge enabled, or if you are using a PostgreSQL database and the PostgreSQL schema which you are connected to has the JChem PostgreSQL Cartridge enabled, then you can choose between five different types of structure entities:
| Entity | Description |
|---|---|
| Structure entity (using JChem base table) |
These are the normal JChem tables that are also present in the non-Oracle databases. When using this table type all processing (including searching) takes place inside IJC and uses IJC memory. For large structure tables (100,000 structures or more) you may need to ensure that you have additional memory allocated to IJC. |
 Structure entity (using standard table) Structure entity (using standard table) |
These are standard (non-JChem) database tables which have had a JChem cartridge index applied to their structure column. This allows the table to be searched in a chemically intelligent manner. All operations are performed using SQL operations in the Oracle database and there is very little processing or memory required from IJC. For this reason, very large tables (multi-millions of structures) can be searched in IJC with normal memory requirements. |
 Structure entity (using JChemBase table) Structure entity (using JChemBase table) |
These are JChem database tables that have had a JChem cartridge index applied to the cd_structure column to allow it to be searched using Oracle SQL operations. This type of entity is a hybrid of the first 2 types. Whilst searching is performed in Oracle, many other operations such as addition of chemical terms fields are performed using the JChemBase API. Because of this the JChem (running in the Oracle cartridge) and IJC version must be the same. If the JChem and IJC versions are different, some features of this table type will be disabled. For this reason, the cartridge entity using standard tables is preferred. |
 Structure entity (using PostgreSQL Cartridge table) Structure entity (using PostgreSQL Cartridge table) |
These are special PostgreSQL cartridge tables with the structure column type MOLECULE('sample') which is searched in a chemically intelligent manner. All operations are performed using SQL operations in the PostgreSQL database which places very little processing or memory requirements on IJC. For this reason, very large tables (multi-millions of structures) can be searched in IJC with normal memory requirements. |
 Structure entity (using Oracle Choral Cartridge table) Structure entity (using Oracle Choral Cartridge table) |
These are special Oracle cartridge tables with the Choral cartridge structure index. All operations are performed using SQL operations in the Oracle database which places very little processing or memory requirements on IJC. For this reason, very large tables (multi-millions of structures) can be searched in IJC with normal memory requirements. |
When the conditions listed above are not met, you will only see the first of these five types. Details of how to administer the JChem Cartridge for IJC can be found in the administration guide.
Entity Creation
Creating an entity with Data Tree
When creating an entity, it is often useful to also create a data tree along with its views (grid view or form view). An entity can either be created on its own or it can be created with its new Data Tree.
To create an entity with a new table along with a new Data Tree there are three options:
-
In the Projects window, right-click the Schema node (
 ) and choose 'New Data Tree and structure entity (table)', 'New Data Tree and standard entity (table)', 'New Data Tree and SQL entity (virtual view)' or 'New Data Tree and Pivot entity (virtual view)' from the popup menu .
) and choose 'New Data Tree and structure entity (table)', 'New Data Tree and standard entity (table)', 'New Data Tree and SQL entity (virtual view)' or 'New Data Tree and Pivot entity (virtual view)' from the popup menu . -
Open the Schema Editor and switch to the 'Data Trees' tab. In the Schema Editor toolbar select either the 'New structure entity' icon (
 ) or the 'New standard entity' icon (
) or the 'New standard entity' icon ( ).
). -
Open the Schema Editor and switch to the 'Entities' tab. In the Schema Editor toolbar click on the 'New Entity with Data Tree' icon (
 ) and then select 'New data tree with new structure entity (table)', 'New data tree with new standard entity (table)', 'New data tree with new SQL entity (virtual view)' or 'New data tree with new Pivot entity (virtual view)' as appropriate .
) and then select 'New data tree with new structure entity (table)', 'New data tree with new standard entity (table)', 'New data tree with new SQL entity (virtual view)' or 'New data tree with new Pivot entity (virtual view)' as appropriate .
The New Entity dialog guides you through the process of entity creating. As well as the entity being created you also get a data tree that will be added to the schema editor and the project window.
Creating an entity without Data Tree
To create an entity without a Data Tree, in the schema editor switch to the 'Entities' tab and click on the 'New entity' button in the toolbar (  ). In the pop-down menu choose 'New structure entity (table)', 'New standard entity (table)', 'New SQL entity (virtual view)' or 'New Pivot entity (virtual view)' as appropriate.
). In the pop-down menu choose 'New structure entity (table)', 'New standard entity (table)', 'New SQL entity (virtual view)' or 'New Pivot entity (virtual view)' as appropriate.
Database Table Entity
After selecting New database table as entity type, specify its general settings:
-
In the Display Name text field, enter a name for the new entity.
-
In the Database Table Name text field, the content of the Display Name text field is automatically copied and can’t be changed.
In the second tab (ID Generation), the value generator type can be set. The default value generator type is Autoincrement. Detailed documentation about value generators available in IJC can be found here.
After clicking Finish, a new standard entity is created in your project as well as a new database table. If you have requested to create a new data tree together with the new entity, it is also created. The node for a simple Data Tree ( ) is displayed under the appropriate database connection in the Projects window and in the 'Data Trees' tab of the schema editor.
) is displayed under the appropriate database connection in the Projects window and in the 'Data Trees' tab of the schema editor.
JChem PostgreSQL Cartridge Entity
If you are using a PostgreSQL database and have the JChem PostgreSQL Cartridge installed and running, a new JChem PostgreSQL Cartridge entity can be created. (Documentation pages about installation and administration of the JChem PostgreSQL Cartridge can be found here.) After selecting the JChem PostgreSQL Cartridge entity as entity type, the following settings need to be specified:
-
In the Display Name text field, enter a name for the new entity.
-
In the Database Table Name text field, the name of the new entity is automatically copied from the Display Name text field.
-
In the Structure Column field, enter a name for the structure column in the database table.
-
In the ID column field, specify the column name for the identity column (primary key column) in the database table. For a JChem PostgreSQL Cartridge entity, the ID is generated automatically.
-
The default value of the Molecule Type field is ‘sample’. You can add a new molecule type or change the existing one. Detailed documentation about adding and changing molecule types is available in the JChem PostgreSQL Cartridge Manual here.
Structure Entity
When you’re creating a new structure entity (table), the following dialogue appears:
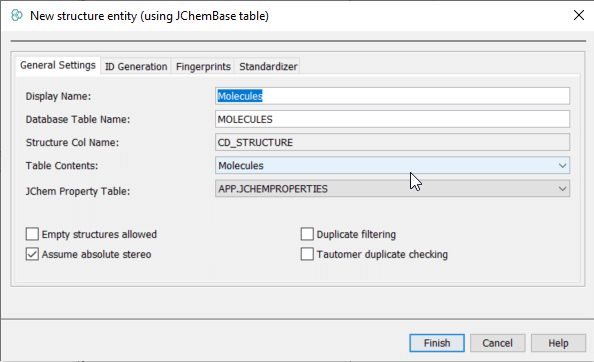
Settings and properties of the new structure entity can be adjusted as follows:
-
Tab 1: General Settings
-
In the Display Name text field, enter a name for the new structure entity.
-
In the Database Table Name text field, the name of the new entity is automatically copied from the Display Name text field.
-
Use the Table Contents drop-down box to specify the structure types to be included in the JChem Structure Table. Choices are:
-
Molecules: discrete structures only
-
Reactions: single step reactions
-
Query structures: structures with query features
-
Markush libraries: structures with Markush features
-
Any structures: all types of structures (including reactions, query structures and Markush structures)
-
-
{primary} If 'Any structures' is selected, structure type-specific search functionality (e.g. reaction searching) will be disabled.
{primary} Markush Libraries requires Markush Enumeration and Markush Search licenses.
-
Specify the settings for the JChem property table and the handling of:
-
Absolute stereo: are chiral structures to be treated as having absolute stereochemistry (the MDL chiral flag option)
-
Empty structures allowed: are empty structures allowed in the table.
-
Duplicate filtering on/off: is duplicate filtering currently enabled.
-
Tautomer duplicate checking: does duplicate filtering consider tautomeric structures (has no effect if the previous option is set to off, but does effect on creating the table).
-
{primary} If you are using a JChem cartridge enabled schema, you will be able to choose between different types of structure tables. Some options are available only for specific cartridge tables. Please see the About the JChem cartridge table types documentation page for more details.
-
Tab 2: ID Generation
- Specify details and the value generation method for the primary key column. In JChemBase, this is set automatically by JChem and there are no user-defined settings. For JChem cartridge indexes on standard tables, you need to define the ID generation method. See the section on primary keys for more details.
-
Tab 3: Fingerprints
- Optionally, the chemical hashed fingerprint settings can be specified. These affect the structure search performance. The default fingerprint settings are dependent on the table type (e.g. fingerprints for reaction table type are longer than for molecules). The default settings are suitable in most cases. For specific details of fingerprint settings consult the JChem Administration Guide.
-
Tab 4: Standardizer tab
- Optionally set details for the standardizer. Default standardization will be used if no custom standardization is specified. Default standardization involves conversion to aromatic form and removal of explicit hydrogen atoms. See the section on standardizing structure files for details of using the standardizer editor or the JChem Query Guide for a discussion of standardization and structure searching. Please note, the standardizer actions require a Standardizer license.
-
Click Finish.
- A new entity is created in your project, as well as a JChem table in the database. A new data tree node for a simple Data Tree (
 ) displays under the appropriate database connection in the Projects window and the 'Data Trees' tab of the schema editor.
) displays under the appropriate database connection in the Projects window and the 'Data Trees' tab of the schema editor.
- A new entity is created in your project, as well as a JChem table in the database. A new data tree node for a simple Data Tree (
For more details regarding the JChem structure tables, please see the JChem Administration Guide.
SQL Entity
When you’re creating a new SQL entity, the following dialogue appears:
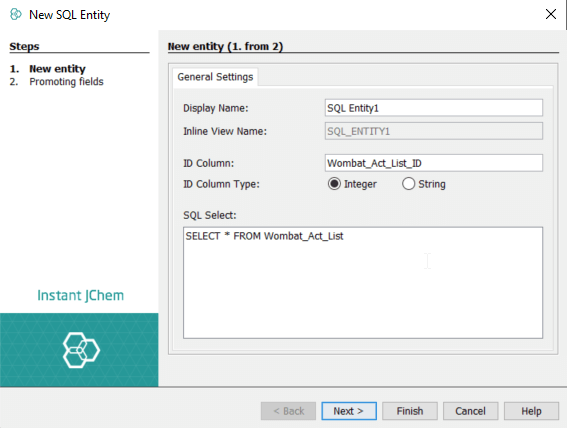
-
Tab 1: General Settings
-
In the Display Name text field, enter a name for the new entity.
-
In the ID Column text field, enter the name of the column with ID values. The ID column must contain unique non-null values. This sets the column as the ID field (primary key column) of the new entity.
-
Choose data type for values in the ID column. IJC supports integer and string ID fields, see the About primary keys and value generators documentation page.
-
In the SQL Select area, specify a SQL SELECT statement to define the new SQL entity. This SELECT must retrieve a column containing the ID column specified in the ID Column text field.
-
Press Next button and continue with promoting fields.
-
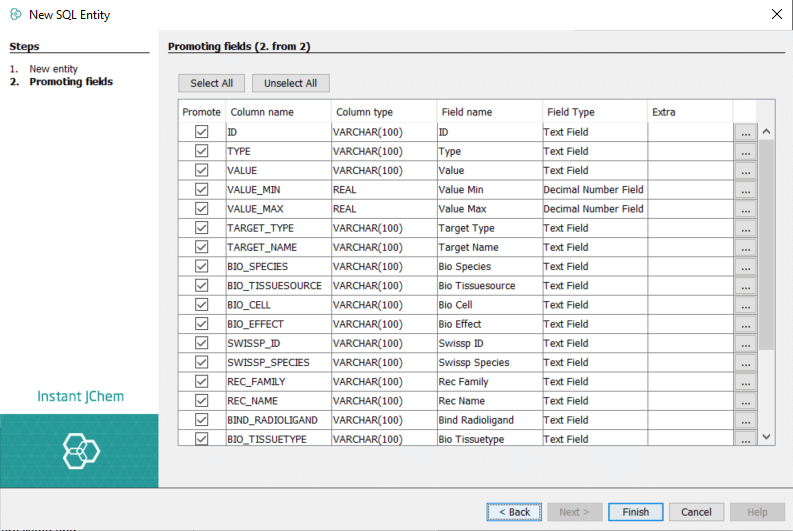
-
Tab 2: Promoting fields
-
All columns retrieved by the SQL SELECT statement are listed and offered for promoting as fields in the new SQL entity.
-
In this step, you can specify which columns you want to promote to fields. The columns can be selected or unselected using the checkboxes next to their names. Additional parameters for each column can be customized by clicking the
 icon in the last column of the table. Columns can be instantly promoted this way. Unpromoted columns can be also added individually to the IJC SQL entity.
icon in the last column of the table. Columns can be instantly promoted this way. Unpromoted columns can be also added individually to the IJC SQL entity.
-
Column aggregation and table pivoting
Both on Oracle database and SQL entity definition, it is possible to use functions LISTAGG and PIVOT.
LISTAGG function
The LISTAGG function rearranges values from a group of rows into a list of values delimited by a separator.
| Value | registration_NO | Date |
|---|---|---|
| value1 | 1 | Jun 1, 2015 |
| value2 | 1 | Jun 3, 2015 |
| value3 | 1 | Jun 2, 2015 |
| value4 | 2 | Jun 4, 2015 |
| value5 | 2 | Jun 5, 2015 |
To aggregate the values with the same registration_NO and sort them according to the date, the following SQL statement can be used:
SELECT registration_NO as ID,
LISTAGG(Value,',') WITHIN GROUP (ORDER BY Date) "Aggregated Values"
FROM TableName
GROUP BY registration_NOThis will result in the following table:
| ID | Aggregated Values |
|---|---|
| 1 | value1, value3, value2 |
| 2 | value4, value5 |
PIVOT function
The PIVOT function enables writing queries to transpose rows into columns and aggregating data in the process of transposing.
| registration_ID | value | assay_id |
|---|---|---|
| 1 | 10 | N1 |
| 1 | 20 | N1 |
| 1 | 30 | N1 |
| 2 | 30 | N1 |
| 2 | 35 | N1 |
| 3 | 35 | N2 |
| 4 | 37 | N2 |
The pivoted table displays the sum of the values for each registration_ID with the same assay_id and can be created with the following SQL statement:
SELECT * FROM
(
SELECT registration_ID AS ID, value, assay_id
FROM TableName
ORDER BY registration_ID
)
PIVOT
(
SUM(value)
FOR assay_id IN ('N1','N2')
)This will result in the following table:
| ID | N1 | N2 |
|---|---|---|
| 1 | 60 | |
| 2 | 65 | |
| 4 | 37 | |
| 3 | 35 |
The outer SELECT is used to display the data from the pivoted table, the inner SELECT defines the fields to be pivoted and defines the ID field needed for proper functionality of the SQL entity in IJC. Inside of the PIVOT clause, the desired analytic function (SUM) and the pivot condition (inside of the FOR loop) is defined. Unlike SQL, a dynamic statement (subquery) can’t be used in the PIVOT IN clause in Oracle.
Pivot Entity
Creation of a Pivot entity in IJC and its management is described here.
Web Service Entity
The Web Service Entity allows to facilitate the retrieval of data from external sources. As an experimental feature, there are specific setup requirements and capabilities users should be aware of.
Enabling Web Service Entity
To utilize the Web Service Entity, it first needs to be activated:
- Ensure that the Java property
com.chemaxon.dif.enable.wsentityis set totrue. In order to do so, navigate toetc\instantjchem.confand add-J-Dcom.chemaxon.dif.enable.wsentity=trueas can be seen in the screenshot below.
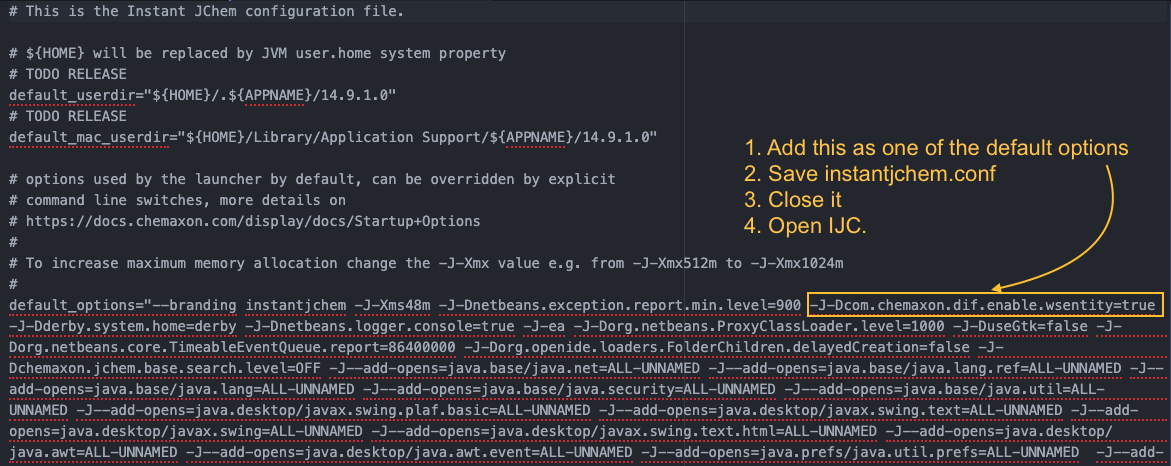
Once activated, a new action titled "New Data Tree and Web Service entity (virtual view)" will be available. This action can be found in the pop-up menu that appears when you right-click on a schema.
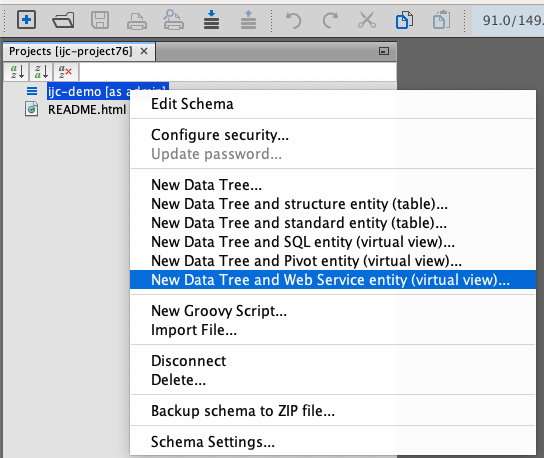
Creating Web Service Entity
To set up a new web service entity, you'll need to provide Display Name and fill in Config. Config should contain structured JSON map that dictates how the entity will function. The key components of Config include:
-
handlerClass: Specify a Java handler class that implements WSEntityHandler.
-
webService: Define the web service's attributes:
-
id: A unique identifier for the web service.
-
description: A brief overview or description of the web service.
-
baseURL: The base URL of the server which will be extended by operation endpoints.
-
operations: An array detailing the operation settings. For each operation, you'll need:
-
id: A unique operation identifier.
-
description: A brief overview or description of the operation.
-
httpMethod: The method type (e.g., GET, POST).
-
endpoint: The URL endpoint, supporting potential format variations.
-
handlerClass: Specify a Java handler class that implements WSOperationHandler.
-
-
A practical example of such configuration might look like this.
{
handlerClass: "com.chemaxon.ijc.wsentity.bioentity.BioEntityHandler",
webService: {
description: "Macromolecules Web Service",
baseURL: "http://macro.web.server:port",
operations: [
{
id: "list-all-macromolecules",
description: "List all registered macromolecules",
httpMethod: "GET",
endpoint: "/api/macromolecules",
handlerClass: "com.chemaxon.ijc.wsentity.bioentity.macromolecule.controller.ListAllMacromolecules"
},
{
id: "retrieve-macromolecule",
description: "Retrieve a registered macromolecule by CID",
httpMethod: "GET",
endpoint: "/api/macromolecules/{0}",
handlerClass: "com.chemaxon.ijc.wsentity.bioentity.macromolecule.controller.RetrieveMacromolecule"
},
{
id: "blast-search",
description: "Perform BLAST search",
httpMethod: "POST",
endpoint: "/api/macromolecule/blast/search",
handlerClass: "com.chemaxon.ijc.wsentity.bioentity.blast.controller.BlastSearch"
}
]
}
}Functionality of Web Service Entity Handler
The handler for the Web Service Entity does the following:
- Returns a list of fields, inclusive of the ID field.
- Provides all row IDs.
- Implements DFDao which allows retrieval of row count and the respective data for each row.
- Returns custom field types and icons.
Capabilities and Limitations
The Web Service Entity is designed to read and potentially update data. However, there are some points to note:
- Search Functionality: By default, the Web Service Entity does not support search functions. However, search capabilities can be implemented using Extension field along with custom operator(s).
- Integration with Other Entities: The Web Service Entity can integrate with other entities using a Virtual Relationship (specifically, a 1:N relationship).
- Java handlers associated with the Web Service Entity are installed via NetBeans plugins.
Support for database views
An IJC entity can be created using a database view. A view is a virtual table in the database containing rows and columns, like a real database table. The fields in a view are fields from one or multiple tables in the database. A view is created by CREATE VIEW statement. Data visualized through the view are defined by SELECT statement. For example, a view can be created as follows:
CREATE VIEW view_name AS
SELECT * FROM table_name This view shows all fields from the original table. For better readable data representation, additional operations can be added by SELECT statement such as combining data from multiple tables, data filtering or pivoting. A view always represents up-to-date data. The database engine recreates the data every time a user queries a view.
A database view is not to be confused with IJC views (grid view and form view) as these are visual reports of data.
The database views are displayed in the ‘Views’ tab of the schema editor and are supported by IJC on a similar way as database tables, with the following limitations:
-
IJC entities, which use views, are read-only.
-
The database views must be created directly in the database, can’t be created in the IJC.
-
The database views are supported only for standard entities in IJC, aren’t supported for structure entities.
Editing an entity
Settings of an entity can be checked and modified from the schema editor. By clicking the entity in the schema editor, the General Settings, ID Generation, Permissions and Extra Attributes tabs are listed in right window. In addition, the Fingerprints, Standardizer and Statistics tabs appear in case of a structure entity. Not all settings are editable once the entity has been created. For instance, the fingerprint settings can be specified when the structure table is being created, afterwards are not editable. The non-editable fields are greyed out in the tabs.
In the General Settings tab, the entity name and the database table name appear. In case of structure entities, the JChem property table settings become visible as well as flags for allowing empty structures and duplicate filtering and flags for stereochemistry settings (assume absolute stereo and tautomer duplicate checking). Documentation of JChem stereochemistry features can be found here.
The ID generation tab contains two non-editable fields (ID field and type) in case of both standard and structure entities. The ID field works as primary key column in the database table and the values included in this field are autoincrement (for standard entities) or are automatically generated by JChem (for structure entities).
Data modification operations for editing, deleting and inserting rows can be set in the Permissions tab.
A custom row filter for any IJC entity can be added and modified in the Extra Attributes tab. This feature offers restricting access to data at the level of the rows in the database. Instructions for using this feature can be found here.
The Fingerprints, Standardizer and Statistics tabs are visible only for structure entities. In the Fingerprints and Standardizer tabs, the JChemBase table attributes are displayed. These values can’t be modified. By clicking the ‘Generate’ button in the Statistics tab, descriptive statistics data are calculated for values included in the JChem table (NULL SMILES count and SMILES length, chemical fingerprint settings and distribution). More information about chemical hashed fingerprints can be found here.
{primary} A pivot entity has limited editing capabilities, the details can be found in the documentation here.
Deleting an entity
In the ‘Entities’ tab of the schema editor right-click the entity and choose 'Delete...' from the popup menu. You are presented with a dialog informing you of the other changes that this deletion would cause. The checkbox offers the option of not deleting the actual database table (removing the entity from IJC but leaving the table in the database). Review the settings and click the 'Delete' button to perform the deletion.
Promoting an entity
The database may contain tables that are not used by any entity. These might have been in the database before it was used by Instant JChem or might have been created by Instant JChem and then the entity was deleted without the corresponding table being removed. To see these unused tables, use the 'Database Tables' tab of the Schema Editor. For more information on using existing tables in the database see the Using existing database tables documentation page. Oracle database tables from other database schemas can be also accessed and promoted. See the support for multiple database schemas documentation page for more details.